写在前面
上一篇笔记中,我们用比较笨的方式绘制了多个点,效率低,而且无法绘制三角形这样的基本图元,复杂图形就更无从谈起了
一.认识buffer
buffer是WebGL系统内部划分出的一块区域,可以存放一组顶点数据,比如顶点坐标,把顶点数据写入buffer后,着色器程序执行时就可以从buffer中读取数据,在数据量较大时尤为方便
着色器程序中虽然不能直接读buffer,但可以先通过API来指定着色器变量值为buffer的地址,再指定数据读取方式,例如从哪里开始读?读几个数?下一个顶点的数据在哪里?间接地从buffer中读取数据
二.类型化数组
准备顶点数据本来没有必要单独拿出来讨论,但这一步很容易错,正确代码如下:
// 一次性传递一组顶点数据
//!!! 注意:不是一般数组,需要new类型化数组,否则报错
// GL ERROR :GL_INVALID_OPERATION :glDrawArrays: attempt to access out of range vertices in attribute 0
// var arrVtx = [-1.0, 1.0, 1.0, 1.0, -1.0, -1.0, 1.0, -1.0, 0.0, 0.0];
var arrVtx = new Float32Array([-1.0, 1.0, 1.0, 1.0, -1.0, -1.0, 1.0, -1.0, 0.0, 0.0]);
特别注意:准备向buffer写入的数据不是一般数组,需要new类型化数组,否则报错,错误信息如下:
GL ERROR :GL_INVALID_OPERATION :glDrawArrays: attempt to access out of range vertices in attribute 0
单从错误信息很难追溯到顶点数据上,所以才要特别注意
因为GLSL ES是强类型语言,js是弱类型的,js数组元素没有限制,而GLSL ES需要非常严格的数据,所以才有了类型化数组。在WebGL中,类型化数组有以下8种:
Int8Array
UInt8Array
Int16Array
UInt16Array
Int32Array
UInt32Array
Float32Array
Float64Array
区别是每个元素所占字节数不同(类型化数组有BYTES_PER_ELEMENT属性,可以获取数组内每个元素所占字节数,比如Float32Array每个元素占4个字节),与普通数组相比,类型化数组不支持push和pop方法,但针对“大量元素都是同一种类型”做了优化
三.使用buffer
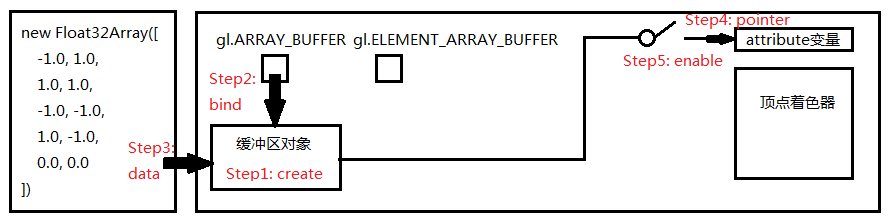
从创建buffer到写入一组顶点数据,我们需要做5件事
1.创建buffer
直接调用API创建buffer,如下:
// 1.创建buffer
var vBuffer = gl.createBuffer();
if (!vBuffer) {
console.log('Failed to create buffer');
return;
}
若创建失败,则返回null,但由于这种函数出错率比较低,此处不做严格的错误判断(而出错率高的部分一定要做严格的判断,比如编译着色器源程序)
2.把缓冲区对象绑定到目标
创建缓冲区后需要把缓冲区对象绑定到WebGL系统中已经存在的target上
// 2.把缓冲区对象绑定到目标
gl.bindBuffer(gl.ARRAY_BUFFER, vBuffer);
buffer都创建好了,下一步不应该是写入数据吗?绑定目标做什么?
因为我们无法直接向缓冲区写入数据,只能向target写入,所以要向缓冲区写数据,必须要先绑定target与buffer。target表示缓冲区对象的用途,值为gl.ARRAY_BUFFER或者gl.ELEMENT_ARRAY_BUFFER,前者表示缓冲区对象包含了顶点数据,后者表示包含了顶点的索引值
3.向缓冲区对象写入数据
通过gl.bufferData(target, data, usage)写入数据
// 3.向缓冲区对象写入数据
gl.bufferData(gl.ARRAY_BUFFER, arrVtx, gl.STATIC_DRAW);
其中data是类型化数组,前面已经介绍过了
usage表示缓冲区数据用途,WebGL会根据用途进行优化,值为gl.STATIC_DRAW(只向缓冲区对象写入一次数据,但需要绘制很多次)、gl.STREAM_DRAW(只向缓冲区对象中写入一次数据,然后绘制若干次)或gl.DYNAMIC_DRAW(向缓冲区对象多次写入数据,并绘制很多次),区别不很明显,而且只可能会影响性能,不会影响最终结果
4.将缓冲区对象分配给a_Position变量
buffer准备好了,现在要给着色器变量赋值,并告诉着色器这些数据待会儿怎么用
// 4.将缓冲区对象分配给a_Position变量
gl.vertexAttribPointer(a_Position, 2, gl.FLOAT, false, 0, 0);
// 等价于
// gl.vertexAttribPointer(a_Position, 2, gl.FLOAT, false, arrVtx.BYTES_PER_ELEMENT * 2, 0);
通过gl.vertexAttribPointer(location, size, type, normalized, stride, offset)给attribute对象赋值缓冲区指针,参数含义如下:
gl.vertexAttribPointer(location, size, type, normalized, stride, offset)
---
size 缓冲区中每个顶点的分量个数(1~4),表示每个顶点数据中要赋值给着色器变量的分量个数
type 数据格式,值为gl.UNSIGNED_BYTE、gl.SHORT、gl.UNSIGNED_SHORT、gl.INT、gl.UNSIGNED_INT、gl.FLOAT五种
normalized true|false,表示是否把非浮点型数据归一化到[0, 1]或者[-1, 1]区间
stride 指定相邻两个顶点间的字节数,默认为0
offset 缓冲区对象中的偏移量,从缓冲区的offset位置开始写,从头开始就是0
特别注意:stride参数比较特别,如果每个顶点有n个数据,把stride置为arr.BYTES_PER_ELEMENT * n的效果和0一样。因为当前顶点数据读取结束后,如果stride为0,则从当前顶点数据结束的位置开始读取下一个顶点的数据,如果stride非0,则从当前顶点数据开始的位置跳过stride指定的字节再开始读取
P.S.可能不好理解,但事实就是这样,我们在以后的具体例子中再解释
5.连接a_Position变量和分配给它的缓冲区对象
buffer准备好了,也告诉着色器数据该怎么用了,最后还要连接变量和缓冲区
//!!! 注意:分配完还要enable连接
// 5.连接a_Position变量和分配给它的缓冲区对象
gl.enableVertexAttribArray(a_Position);
这一步很容易忘记,因为从逻辑上看已经完整了,这一步纯属多余,但API就是这样,这一步就像下图的开关:
webgl-buffer
6.绘制多个点
// 绘制点
gl.drawArrays(gl.POINTS, 0, arrVtx.length / 2);
终于用上了第三个参数,不再是draw a point了,第三个参数表示要绘制的顶点个数,本例中数组长度arrVtx.length除以每个顶点的数据数2表示绘制arrVtx中的全部顶点(共5个)
四.DEMO
包含上述代码的完整的例子,请查看:http://www.ayqy.net/temp/webgl/buffer/index.html
五.总结
本例中,我们用buffer传入了5个点的坐标(4个角以及中心),一次性绘制了出来,解决了最基本的输入数据的问题
解锁了buffer后就可以去摸摸图元以及稍复杂的图形了,下一篇笔记中我们要画最神奇的图元——三角形。这样夸三角形真的没错,事实上,三角带可以拼出整个世界,人物模型、BOSS模型、花草树木等等一切都是三角带拼出来的
参考资料
- 《WebGL编程指南》