写在前面
理论上,有了可靠的负载均衡机制,我们就能将 1 台服务器轻松扩展到 n 台,然而,如果这 n 台机器仍然使用同一数据库的话,很快数据库就会成为系统的性能瓶颈和可靠性瓶颈
那么,如何提升数据库的处理能力?
从资源的角度来看,无非两种思路:
纵向扩展:提升单机配置(硬盘、内存、CPU 等等),但同样会遭遇单机性能瓶颈
横向扩展:增加机器,数量上从单数据库实例扩展到多实例
这样看来,似乎只要加几个数据库,共同分担来自应用层的流量就完成了从单库到多库的扩展:
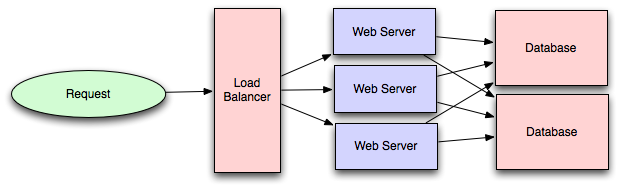
果真如此简单吗?
一.一致性问题
如果同一数据存在多份拷贝,那么就需要考虑如何保证其一致性
(摘自一致性模式)
数据库与应用服务最大的区别在于,应用服务可以是无状态的(或者可以将共享状态抽离出去,比如放到数据库),而数据库操作一定是有状态的,在扩展数据库时必须要考虑数据的一致性
具体的,一致性分为 3 种,严格程度依次递减:
强一致性(Strong consistency):写完之后,立即就能读到
最终一致性(Eventual consistency):写完之后,保证最终能读到
弱一致性(Weak consistency):写完之后,不一定能读到
二.Replication
所以,从单库扩展成多库,至少要有一种数据更新同步机制,称之为Replication(复制):
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
即,通过复制(写操作)来保证多份数据拷贝的信息一致性。例如,向数据库实例 A 写入数据时,也要把相同的数据写入到实例 B、C、D 等
三.复制方式
异步复制
具体的,可以在写完之后,再告知其它实例更新数据,即异步复制(Asynchronous replication):
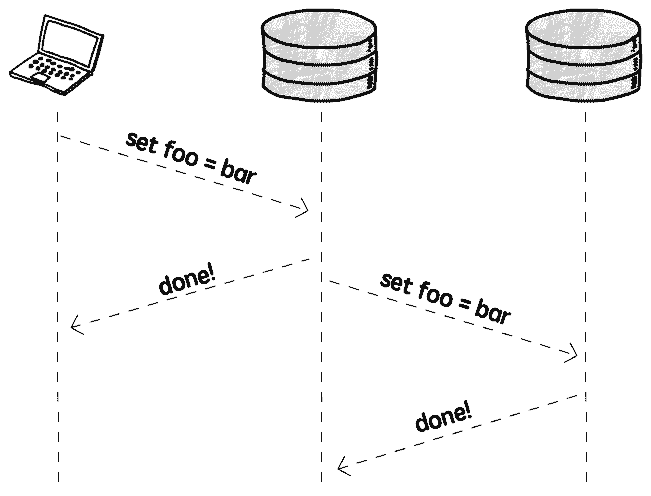
这种模式下,客户端无需等待复制操作完成,不存在额外的性能影响。但问题在于:
有数据丢失风险
无法保证强一致性,因为存在复制延迟(Replication lag)
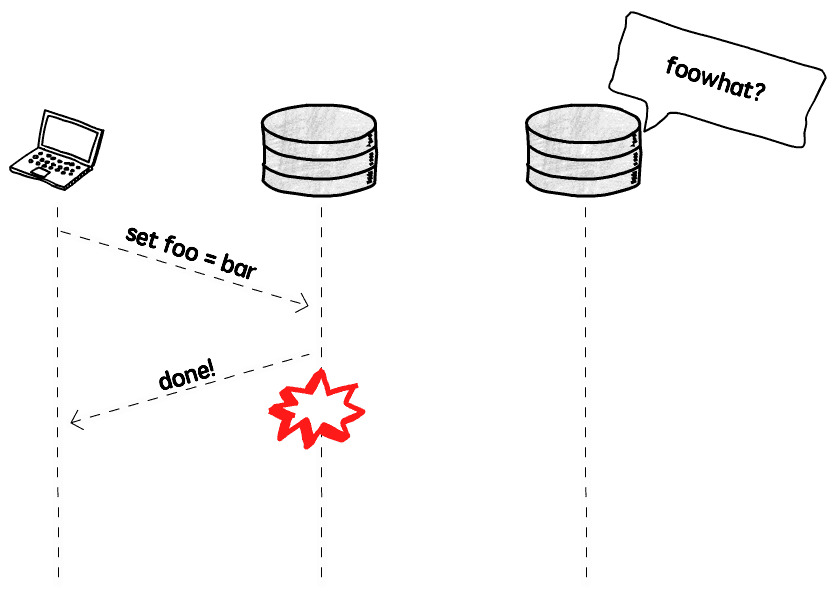
如果实例 A 在写完之后,还没来得及告知其它实例,自己却 down 掉了,就会出现数据丢失:
另一方面,由于复制操作是异步完成的,数据更新实际上是滞后的:
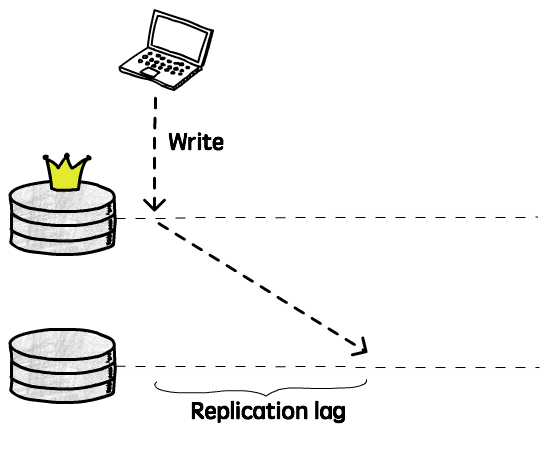
从当前实例上一个写操作完成,到该操作被应用到其它实例的时间差称为复制延迟(Replication lag)。在这期间,客户端从其它实例上读到的仍然是旧数据,显然不满足强一致性的要求(仅能保证最终一致性)
同步复制
想要达到严格的一致性要求,不得不考虑同步复制(Synchronous replication):
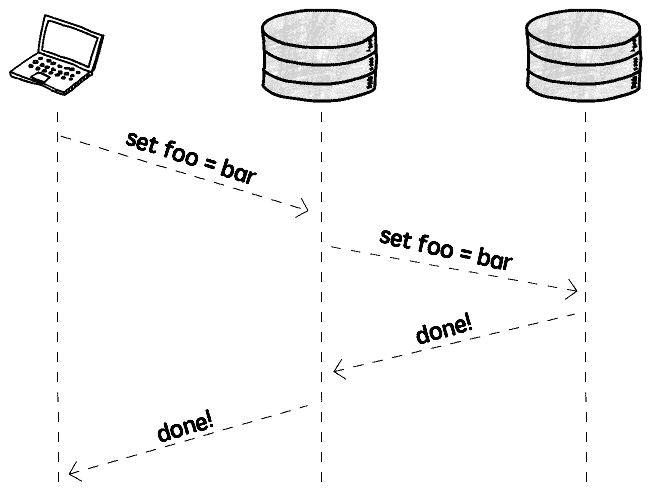
发生写操作时,立即将操作同步到其它所有实例,复制完成之后才算写完,以确保严格的一致性
但同步复制会影响性能和可用性,代价颇高:
性能影响:需要等待整个复制过程完成
可用性影响:只要有一个实例出现故障(网络等原因),整个写操作就会失败
并且数据库实例数量越多,这两方面的影响越大
半同步复制
特殊地,可以将两种方式结合使用,称之为半同步复制(Semi-synchronous replication):
Some databases and replication tools allow us to define a number of followers to replicate synchronously, and the others just use the asynchronous approach. This is sometimes called semi-synchronous replication.
即要求一部分数据库实例同步复制,其余的异步复制
P.S.PostgreSQL支持这种模式
四.拓扑结构
拓扑结构上,复制可以分为 3 类:
单主结构(Single leader replication)
多主结构(Multi leader replication)
无主结构(Leaderless replication)
单主结构
即最常见的一主多从结构:
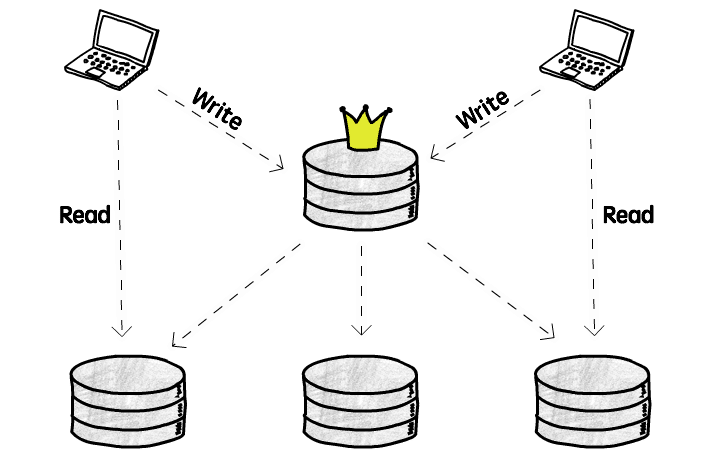
这种结构下,写操作(增/删/改)只允许发生在主库,由主库将写操作复制到其它所有从库,从库只支持读操作(查)
由于所有客户端都写同一个库,成功避免了写操作冲突的大麻烦。但要注意的是:
承载写操作压力的仍然是单库:不适用于写密集(write-intensive)的应用,但好在大多数应用都是读密集的
访问主库的延迟问题:主库只有一个,只能放在某个确定的地理位置,意味着在某些区域发起写操作(访问主库)可能要承担较高的延迟
更糟糕的情况,如果主库 down 掉了,需要立即在从库中选出一个接班人,担起主库的职责,保证这套机制正常运转
然而,这种故障转移策略却不那么容易实现,难点在于:
如何确定主库真的 down 掉了?
如何选择新任主库?
如何将写操作转到新任主库上?
实际上,我们无法区分高延迟和不可用,通常认为超时就算不可用(无论是不是真的 down 掉了),接着启动故障转移预案,开始选择新任主库
选出一个不难,关键在于所选的新任主库要被其它所有从库认可其地位才算(即共识问题),比如预先定好接班次序
新任主库选出来之后,要将所有写操作转发过来,比如增加一层分发机制,以允许路由控制
另外,如果采用的是异步复制,旧主库恢复之后,尚未复制到其它从库的数据与掉线期间新任主库写入的数据可能会出现冲突,此时通常采用 LWW(last-write-win)策略,直接丢弃旧数据,但同样存在风险
特殊的,一种有意思的情况是旧主库恢复过来以为自己还是主库,出现分裂(Split-brain):
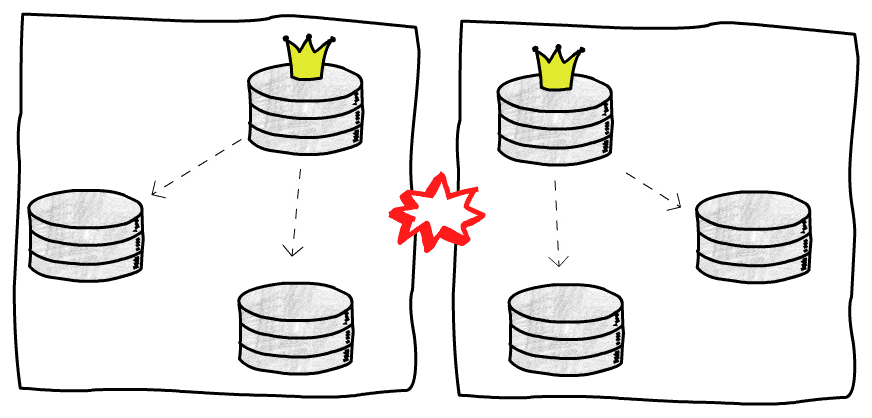
P.S.网络故障也会导致这样的情况,例如两个集群之间出现网络故障,无法互相访问,都以为另一队人马挂掉了,于是各自开始大选
简单的处理办法是 STONITH(Shoot The Other Node In The Head),一旦发现存在多个主库,直接停掉一个
多主结构
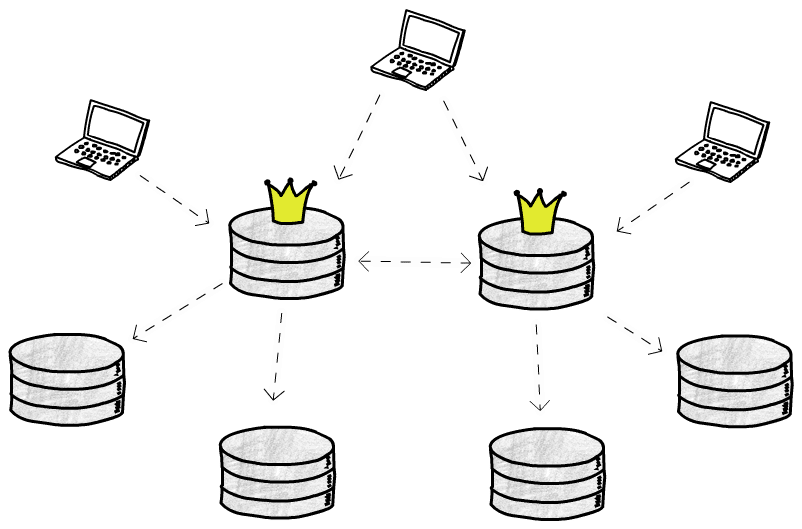
现在有了多个可写的主库,可以分担写操作,也可以多地部署,单主结构的 2 个问题迎刃而解。然而,大麻烦却出现了
由于写操作能够同时发生在(异步复制的)多个库,我们必须考虑如何解决写入冲突。一般有 3 种思路:
避免冲突:比如按内容特征分库存储,互不相干,比如对于国内国外两个主库,如果能够保证所有对国内数据的写操作都能落到国内主库上,所有对国外数据的写操作都能落在国外主库上,就不存在冲突了
LWW(last-write-win)策略:给每个写操作带上时间戳,只保留最新版本
交由用户来解决:记下冲突,应用程序提示给用户,由用户决定保留哪一份
P.S.有些数据库(如CouchDB)支持将所有冲突值都写下来,并在读取时返回一系列值
此外,多主结构下的另一个难题是复制 DDL(Data Definition Language),即针对 Schema 的写操作,具体见DDL replication
无主结构
当然,还有一种不区分主库的结构,所有库都可读可写
看起来像是“全主结构”,那么可预见的,写冲突将变得非常普遍,所以我们需要调整策略,避免使之成为“全主结构”:
写:客户端同时向多个数据库写,只要有一些成功了就算写完
读:客户端同时从多个数据库读,各个库返回数据及其对应的版本号,客户端根据版本号来决定采用哪个
没有主库,意味着不需要考虑故障转移,单库故障不影响整体,选择新任主库的各种麻烦问题都不复存在了
同时,没有主库也意味着没有了数据同步机制,读到的旧值无法自动更正:
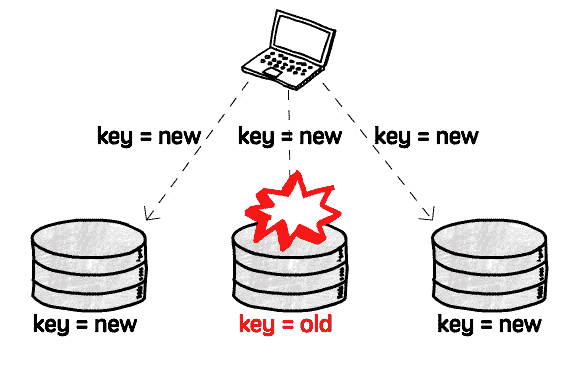
所以需要额外的纠错机制,客户端在读到旧值时将新值写回去(称为Read repair),或者由独立的进程专门负责找出旧值并纠正回来
另一个关键因素是读/写操作的目标库数量,至少几个库写入成功后,至少从几个库成功读取才能保证一定能读到新值?
如果w个库写入成功,接着成功读到了r个库的数据,那么必须满足w + r > 库的总数
五.具体实现
具体的,把一些数据从一个库拷贝到另一个库有 3 种方式:
基于语句的复制:将写操作语句原样发一份给其它库执行
日志传送式复制:也叫物理复制,将数据库日志传递给其它库,从日志恢复出完全一致的数据。例如 PostgreSQL 提供的Streaming Replication
基于行的复制:也叫逻辑复制,传递专门用于复制的日志,按行复制。例如MySQL提供的的Mixed Binary Logging Format
按语句复制的问题在于,并不是所有语句的执行结果都是确定的,例如CURRENT_TIME()、RANDOM(),虽然一些数据库会在复制时对这些值进行替换,但仍无法保证触发器,以及用户定义的函数有确定的执行结果。另一方面,还要确保事务操作在所有数据库上的原子性,要么全都完成了,要么全都一点儿没做
日志传送式复制能够保证数据完全一致,但(面向存储引擎的)日志通常无法跨数据库版本使用,因为在不同版本的数据库下,数据的物理存储方式可能会发生变化。并且,日志传送不适用于多主结构,因为无法把多份日志合并成一份
而基于行的复制是前两种方式的结合,采用一种专门用于复制的日志,不再与存储引擎耦合,因而能够跨数据库版本使用。与按语句复制相比,按行复制需要记录更多的信息(比如一个语句影响了 100 行,需要按行都记下)