一.UI层的松耦合
松耦合就是要求各层遵循“最少知识原则”,或者说是各层各司其职,不要越权:
HTML:结构层
CSS:表现层
JS:行为层
对于各层的职能,有一句比较贴切的解释:HTML是名词(n),CSS是形容词(adj)和副词(adv),JS是动词
因为三层联系紧密,实际应用中很容易越权:
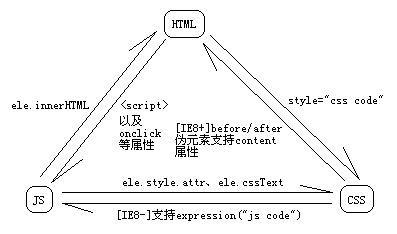
1.从css中分离js
尽量不要用css表达式,如果非要用也应该把相应的代码放在hack中,便于维护
2.从js中分离css
不要用ele.style.attr及ele.cssText,应该用操作类名代替
3.从html中分离js
不要用onclick等属性直接指定事件处理函数,应该用添加事件处理器方式代替
一般不要用<script>标签直接嵌入js代码,尽量放在外部js文件中。当然,对于功能单一且不需要复用的代码可以直接嵌在HTML中,例如表单验证代码
4.从js中分离html
不要直接用innerHTML硬编码,可以用以下3种方式代替:
用Ajax从服务端获取HTML串,避免硬编码
用简单的客户端模版,有2种实现方式:
用注释携带模式串
用script标签携带模式串,把type属性设置为浏览器无法识别的值,还应该给script标签设置id属性以便于获取模式串,例如:
<script type="text/x-my-template" id="list-item"> <li><a href="%s">%s</li> </script>推荐使用这种方式,因为更容易获取模式串
用复杂的客户端模版,比如jade、ejs
P.S.因为html与css的解耦与js编程没有关系,所以书中也没有相应内容
二.少用全局变量
1.全局变量带来的麻烦
命名冲突
代码不健壮,函数需要的所有外部数据都应该用参数传进来,而不要用全局变量传参
难以测试,需要重建整个全局环境
2.隐式全局变量
不要用隐式全局变量方式声明全局变量,建议所有变量声明都带上var关键字
为了避免隐式全局变量,还应该开启严格模式(”use strict”;),[IE10+]支持
3.单全局变量方式
用命名空间,提供一个避免命名空间冲突的方法:
// 顶级命名空间 var app = { /* * 创建/获取子命名空间,支持链式调用 */ namespace: function(ns) { var parts = ns.split("."), object = this, i, len; for (i = 0, len = parts.length; i < len; i++) { if (!object[parts[i]]) { object[parts[i]] = {}; } object = object[parts[i]]; } return object; // 支持链式调用 } } // 测试 app.namespace("Consts").homepage = "http://ayqy.net/"; app.namespace("Consts").author = "ayqy"; // http://ayqy.net/, ayqy alert(app.Consts.homepage + ", " + app.Consts.author);模块化
AMD/CMD,一点扩展知识如下:
CommonJS是一套理论规范(比如js的理论规范是ES),而SeaJS, RequireJS都是对CommonJS的Modules部分的具体实现
CommonJS是面向浏览器外(server端)的js制定的,所以是同步模块加载,SeaJS是CommonJS的一个实现,而RequireJS虽然也是对CommonJS的一个实现,但它是异步模块加载,算是更贴近浏览器的单线程环境
总结:CommonJS的Modules部分提出了模块化代码管理的理论,为了让js可以模块化加载,而RequireJS, SeaJS等各种实现可以称为模块化脚本加载器
CMD:Common模块定义,例如SeaJS
AMD:异步模块定义,例如RequireJS
都是用来定义代码模块的一套规范,便于模块化加载脚本,提高响应速度
CMD与AMD的区别:
CMD依赖就近。便于使用,在模块内部可以随用随取,不需要提前声明依赖项,所以性能方面存在些许降低(需要遍历整个模块寻找依赖项目)
AMD依赖前置。必须严格声明依赖项,对于逻辑内部的依赖项(软依赖),以异步加载,回调处理的方式解决
4.零全局变量方式
用IIFE(匿名函数立即执行)实现,针对不需要复用的功能模块可以用IIFE完全消除全局变量,所以一般IIFE都是用来辅助命名空间/模块化方式的
三.事件处理
1.典型用法(不好)
// 事件处理器
function handleClick(event) {
var popup = document.getElementById("popup");
popup.style.left = event.clientX + "px";
popup.style.top = event.clientY + "px";
popup.className = "display";
}
// 添加事件处理器
ele.addEventListener("click", handleClick);
2.分离应用逻辑(稍好一点)
var app = {
// 事件处理
handleClick: function(event) {
this.showPopup(event);
},
// 应用逻辑
showPopup: function(event) {
var popup = document.getElementById("popup");
popup.style.left = event.clientX + "px";
popup.style.top = event.clientY + "px";
popup.className = "display";
}
};
// 添加事件处理器
// P.S.事件处理器是一个方法声明,而不是方法调用,无法传参,所以需要多一层匿名函数
ele.addEventListener("click", function() {
app.handleClick(event);
});
3.不要传递事件对象(最好)
var app = {
// 事件处理
handleClick: function(event) {
this.showPopup(event.clientX, event.clientY); // 参数变了
},
// 应用逻辑
showPopup: function(x, y) { // 形参变了
var popup = document.getElementById("popup");
popup.style.left = x + "px";
popup.style.top = x + "px";
popup.className = "display";
}
};
// 添加事件处理器
ele.addEventListener("click", function() {
app.handleClick(event);
});
“不要传递事件对象”是一条优化原则,在js高程的优化部分也有提到过,但本书给出了详细理由
直接传递事件对象存在以下缺点:
接口定义不明确,参数作用未知
难以测试(重建一个event对象?)
四.少与null比较
1.检测基本值
用typeof检测,但要注意typeof null返回object,这不太科学,因为js认为null是一个空对象的引用
但用 === null检测DOM元素是合理的,因为null是document.getXXByXXX的可能输出之一
2.检测引用值
instanceof并不能准确地检测子类型,而且不要用它检测fun和arr,因为不能跨frame
- 检测fun
用typeof检测一般方法;用in检测DOM方法
- 检测arr
用Object.prototype.toString.call(arr) === "[Object Array]"检测
注意:ES5有原生的Array.isArray()方法,[IE9+]支持
3.检测属性
用in配合hasOwnProperty()检测
注意:[IE8-]的DOM元素不支持hasOwnProperty(),用的时候要先检测
五.分离配置数据
1.配置数据有哪些?
硬编码的值
将来可能会变的值
比如:
URL
需要显示给用户的字符串
重复使用的唯一值
设置(例如每页显示多少列表项)
可能会变的任何值(不好维护的东西都算配置数据)
2.分离配置数据
先从应用逻辑中分离出配置数据,最简单的可以把所有配置数据分级存放在自定义的config对象中
3.存储配置数据
可以用js文件存储配置数据,便于加载,但配置数据要严格符合js语法,容易出错。作者建议把配置数据存储为格式简单的属性文件再用工具转换为JSON/JSONP/js格式文件用于加载,作者推荐一个自己写的工具props2js
六.抛出自定义错误
1.Error的本质
用来标志出乎意料的东西,避免静默失败,便于调试
2.用js抛出错误
不要抛其它类型,要抛Error对象,因为兼容性,例如:
throw "error: invalid args"; // 有些浏览器不显示该字符串
3.抛出错误的优点
精确定位错误,建议错误信息格式:函数名 + 错误原因
4.何时该抛出错误
只抛常用方法(工具方法)中的错误,一般原则:
修复了奇葩bug之后,应该添几个自定义错误,防止错误再次发生
如果写代码的时候觉得某些点可能引起大麻烦,就应该抛出自定义错误
如果代码是写给别人用的,应该想想别人使用的时候可能遇到哪些问题,应该在自定义错误中给出提示
5.try-catch语句
finally不常用,因为会影响catch中的return
不要留空的catch块,静默失败可能会把问题变得更麻烦
6.几种错误类型
可以抛出原生的几种错误类型实例,配合instanceof做针对性错误处理
P.S.关于具体的几种错误类型以及错误处理的更多信息,请查看黯羽轻扬:JS学习笔记8_错误处理
七.尊重对象所有权
1.哪些对象不属于我们?
原生对象(Object、Array等等)
DOM对象(比如document)
BOM对象(比如window)
库对象(比如JQuery)
2.具体原则
不要重写方法
不要添新方法,非要改库功能的话,可以给库开发插件
不要删除方法,不想用的不要删除,标明过时即可
注意:delete对原型属性无效,只对实例属性有用
function Fun() { this.attr1 = 1; // 实例属性 } Fun.prototype.attr2 = 2; // 原型属性 // 测试 var obj = new Fun(); alert(obj.attr1 + ", " + obj.attr2); // 1, 2 delete obj.attr1; delete obj.attr2; alert(obj.attr1 + ", " + obj.attr2); // undefined, 2 delete Fun.prototype.attr2; alert(obj.attr1 + ", " + obj.attr2); // undefined, undefined
3.更好的方式
基于对象的继承
也就是clone一个新对象,新对象是属于自己的,可以随便改
基于类型的继承
注意:不要继承DOM/BOM/Array,因为支持性不好
P.S.关于对象继承/类型继承的具体实现,请查看黯羽轻扬:重新理解JS的6种继承方式
外观模式
其实就是组合,因为继承/组合都是实现代码复用的方式,关于外观模式的更多信息请查看黯羽轻扬:设计模式之外观模式(Facade Pattern)
一点题外话:facade与adapter的区别是前者创建了新接口,后者只是实现了已存在的接口,作者一针见血
4.polyfill的优缺点
polyfill 是“在旧版浏览器上复制标准 API 的 JavaScript 补充”。“标准API”指的是 HTML5 技术或功能,例如 Canvas。“JavaScript补充”指的是可以动态地加载 JavaScript 代码或库,在不支持这些标准 API 的浏览器中模拟它们。因为 polyfill 模拟标准 API,所以能够以一种面向所有浏览器未来的方式针对这些 API 进行开发,最终目标是:一旦对这些 API 的支持变成绝对大多数,则可以方便地去掉 polyfill,无需做任何额外工作。
关于polyfill的更多信息请查看博客园:[译]shim和polyfill有什么区别?
优点:不需要的时候很容易去掉
缺点:如果polyfill的实现与标准不完全一致就麻烦了
建议不要用polyfill,应该用原生方法 + 外观模式来代替,这样更灵活
5.防篡改
应该开严格模式,因为非严格模式下静默失败难以调试
八.浏览器检测
1.UA(User Agent)检测
非要UA检测的话,尽量向后检测而不是向前,因为后面的不会再变了
P.S.作者认为不用管UA会不会变,理由是会设置UA的用户应该也知道这样做的后果
2.特性检测
特性检测的一般格式如下:
尝试标准方式
尝试特定浏览器的实现方式
不支持的话要给出逻辑反馈(比如return null)
例如:
function setAnimation (callback) {
// 1.尝试标准方式
if (window.requestAnimationFrame) { // standard
return requestAnimationFrame(callback);
}
// 2.尝试特定浏览器的实现方式
else if (window.mozRequestAnimationFrame) { // Firefox
return mozRequestAnimationFrame(callback);
}
else if (window.webkitRequestAnimationFrame) { //WebKit
return webkitRequestAnimationFrame(callback);
}
else if (window.oRequestAnimationFrame) { // Opera
return window.oRequestAnimationFrame(callback);
}
else if (window.msRequestAnimationFrame) { // IE
return window.msRequestAnimationFrame(callback);
}
// 3.不支持的逻辑反馈
else {
return setTimeout(callback, 0);
}
}
3.杜绝特性推断
不能根据一个特性推断另一个特性,因为长得像鸭子的东西不一定也像鸭子一样呱呱叫
4.杜绝浏览器推断
不要根据特性去推断浏览器,比如典型的:
if (document.all) { // IE
// ...
}
这样做是不对的,不应该尝试用特征去描述一个东西,很容易因为条件过少或者过多导致描述不准确
5.到底应该用哪一个?
尽量用直接特性检测,不行才用UA检测。至于推断,就根本不考虑了,没有任何理由去用推断
参考资料
- 《Maintainable JavaScript》