写在前面
对于关系型数据库,(必要时)我们可以通过反范式化牺牲一部分写入性能,来换取更高的读取性能,但前提是先要满足范式设计,接着在此基础上进行局部调整,故意打破一些规则
与其先范式化,遭遇性能瓶颈再进行反范式化,不如从一开始就考虑反范式设计——直接采用 NoSQL
一.什么是 NoSQL?
不同于关系型数据库,NoSQL 数据库(也叫非 SQL 或非关系型数据库)提供的数据存储、检索机制并不是基于表关系建模的:
A NoSQL (originally referring to “non SQL” or “non relational”) database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
没有了数据表,自然就没有了多表连查(join操作)的性能顾虑,范式约束和反范式化的抉择也就不复存在了
可是,没有了数据表,数据该如何组织,关系要怎样描述呢?
实际上,SQL(关系型数据库)并不是唯一的选择
Not Only SQL
对于 NOSQL,另一种有趣的理解是 Not Only SQL,在关系型数据库之外的广阔世界里,数据不一定非要打平存放到二维表格里,关系也不是只能用主键、外键、关系表来描述
就数据库类型而言,NoSQL 指的是除关系型以外的其它类型的数据库,即非关系型数据库(NoREL, Non Relational),例如MongoDB、CouchDB等
从使用角度来看,践行 NoSQL 并不一定先要选个 NoSQL 数据库,以“NoSQL”的方式来使用 MySQL 等关系型数据库当然也算:
You can stay with MySQL, and use it like a NoSQL database.
比如在数据表中存一列 JSON 字符串,把这一列当作键值数据库来用
二.4 种 NoSQL 数据库
不同于关系型数据库中的表结构,NoSQL 数据库支持一些更灵活的数据结构,使得某些操作更快
键值存储
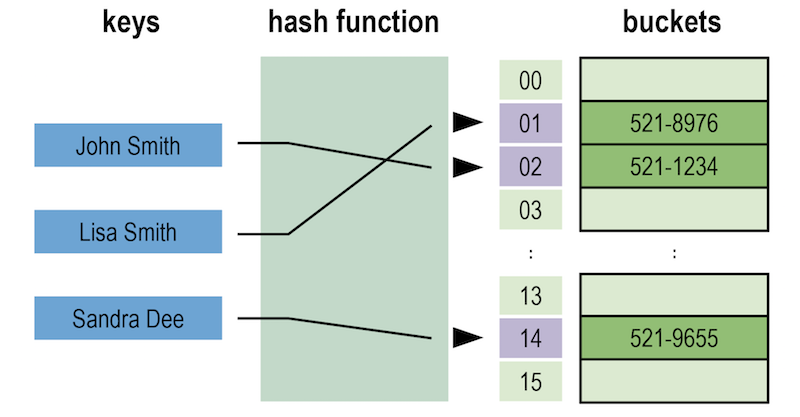
键值存储(Key-value store)是最简单的 NoSQL 数据模型,只能存键值对儿,只能按 key 查询,因为所存储的值对数据库系统不透明(类似于 BLOB),无法根据值的特征查找或建立索引
P.S.有些键值数据库能够对 key 进行排序,从而支持范围查询(检索 key 在特定区间内的数据),比如找出工号大于 100000 的新人信息
数据模型上是个哈希表,因此能够达到O(1)的读写性能,适用于简单、或者频繁更改的数据,经常用作内存缓存,例如Memcached、Redis
文档存储
文档存储(Document store)以文档(XML、JSON 等半结构化数据)为中心建模,相当于增强版的键值存储,面向文档提供更精细的数据操作。与键值存储最大的区别在于数据库能够理解并处理所存储的值(即文档),根据值的特征(即文档的内部结构)查询和建立索引
此外,文档还支持嵌套,甚至MongoDB、CouchDB等文档数据库还提供了类 SQL 的查询语言,以支持复杂查询
适用于持久化存储,用来存放不经常更改的数据,作为关系型数据库的一般替代方案
宽列存储
宽列存储(Wide column store)中,列(column)是最小的数据单元,每一列是个名值对儿(以及用于版本控制和冲突解决的时间戳),在列之上还有一级超级列(super column):

仅含列的行称为列族(column family),含有超级列的行称为超级列族(super column family),每一行(即,一个列族或超级列族)代表一个实体,包含该实体的所有相关信息:

数据模型上是个二维 Map,特点是高性能以及良好的扩展性,因此适用于非常大的数据集,被 Twitter、Facebook 等社交网络用来存储海量用户所产生的数据
P.S.例如 Google 最早推出的Bigtable、Hadoop 生态中的HBase,以及 Facebook 推出的Cassandra
图形数据库
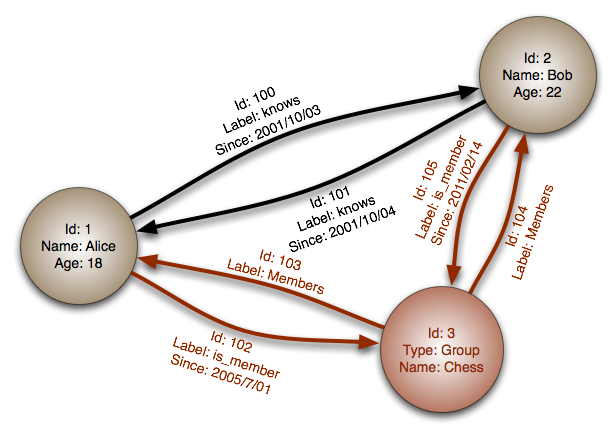
数据基于图来建模,图中每个节点代表一条记录,每条边表示节点之间的关系,因此能够轻松描述数据对象之间的复杂关系,比如关系模型中复杂的外键和多对多关系
图形数据库的实际应用还不十分成熟,甚至还没有一种被广泛采用的标准化查询语言,但其连接性优势尤其适用于具有复杂关系的数据模型(比如社交网络),值得期待:

P.S.例如Neo4j、Oracle Spatial and Graph、ArangoDB等
三.NoSQL 意味着什么?
采用简单的 NoSQL 模型(如键值存储),相当于把一部分工作从数据库层转移到了应用层:
Joins will now need to be done in your application code.
与数据库层相比,应用层通常更容易(横向)扩展,因此这种工作量转移有助于提升系统的可扩展性,将复杂的数据操作抛给应用层来处理,以求更大的优化空间
甚至事务等强一致性保证也要由应用层来处理,因为多数 NoSQL 数据库并不提供事务支持:
Most NoSQL stores lack true ACID transactions, although a few databases have made them central to their designs.
ACID vs. BASE
不同于关系型数据库中追求的ACID(事务的 4 大特性):
Atomicity(原子性):一系列操作要么全部成功要么失败全部回滚
Consistency(一致性):事务执行前后数据库都必须处于一致性状态(满足既定的所有一致性约束)
Isolation(隔离性):并发事务操作的结果状态与按顺序执行一样
Durability(持久性):事务一旦提交,对数据的改变就是永久性的,遭遇故障也不会丢失已提交的结果
NoSQL 在CAP 的抉择中对 C 做了妥协,允许最终一致性,即BASE:
Basically Available(基本可用):读写操作尽可能保证可用,但不保证任何一致性
Soft state(软状态):由于没有一致性保证,在一段时间后,只是有可能读到最新状态,因为可能还没收敛
Eventual consistency(最终一致性):如果系统运行正常,等待足够长的时间后,最终能够读到最新状态
也就是说,在分布式环境下,(大多数)NoSQL 数据库仅保证最终一致性,可能无法立即读到最新的数据
四.SQL or NoSQL?
相比之下,SQL 数据库(关系型数据库)的优势在于:
支持事务操作
有明确的扩展模式
开发人员、社区、工具等相对成熟
主要缺陷是:
复杂的连表查询导致数据读取性能不佳
不太容易扩展(手动分片)
关系模型与 OOP 之间存在较大差异(Object-relational impedance mismatch)
只支持存取结构化数据,关系模式(如表结构)必须预先定义,并且修改成本高
P.S.关于 Object-relational impedance mismatch 的更多信息,见Why is MongoDB wildly popular? It’s a data structure thing.
而 NoSQL 数据库(非关系型数据库)的优势集中在:
不存在复杂的连表查询
容易扩展(一些 NoSQL 数据库支持自动分片)
与 OOP 数据模型一致,易于使用
不必预先定义数据模式,支持存取快速变化的结构化、半结构化和非结构化数据
读写性能(IOPS)很高,适合数据密集型工作
主要缺陷在于:
缺少强一致性保证
开发人员、社区、工具等没那么成熟
应用场景
因此,NoSQL 数据库适用于:
快速变化数据,如点击流(click stream)数据或日志数据
排行榜或评分数据
临时数据,如购物车数据
频繁访问的热点数据
元数据(metadata),以及查找表(lookup tables)