设计思想
想表达什么?React怎样理解Application?
应用是个状态机,状态驱动视图
v = f(d)
v是视图
f是组件
d是数据/状态
与FP有什么关系?
把函数式思想引入前端,通过PureComponent组合来实现UI
最大好处是让UI可预测,对同样的f输入同样的d一定能得到同样的v
可以把各个f单独拎出来测试,组合起来肯定没有问题,从理论上确定了组件质量是可靠的,组合出来的整个应用的UI也是可靠的
目标
想解决什么问题?定位?
A JAVASCRIPT LIBRARY FOR BUILDING USER INTERFACES
针对构建UI提供一种组件化的方案
能解决什么问题?
组件化
UI可靠性
数据驱动视图
性能目标
For many applications, using React will lead to a fast user interface without doing much work to specifically optimize for performance.
寻找成本与收益的平衡点,不刻意去做性能优化,还能写出来性能不错(非最优)的应用
实际上,React所作的性能优化主要体现在:
事件代理,全局一个事件监听
自己有完整的捕获冒泡,是为了抹平IE8的bug
对象池复用event对象,减少GC
DOM操作整合,减少次数
但无论怎样,性能肯定不及年迈的(经验丰富的)FEer手写的原生DOM操作版
虚拟DOM
通过什么方式解决问题?
在DOM树之上加一层额外的抽象
组件化方式:提供组件class模版、生命周期hook、数据流转方式、局部状态托管
运行时:用虚拟DOM树管理组件,建立并维护到真实DOM树的映射关系
虚拟DOM有什么作用?
批处理提升性能
降低diff开销
实现“数据绑定”
具体实现
JSX -> React Element -> 虚拟DOM节点 ..> 真实DOM节点
描述对象
编译时,翻译JSX得到
createElement执行
createElement得到React Element描述对象根据描述对象创建虚拟DOM节点
整合虚拟DOM节点上的状态,创建真实DOM节点
虚拟DOM树的节点集合是真实DOM树节点集合的超集,多出来的部分是自定义组件(Wrapper)
结构上,内部树布局是森林,维护在instancesByReactRootID:
现有app引入React时,会有多个root DOM node
纯React的应用,森林里一般只有1棵树
单向数据流
瀑布模型
由props和state把组件组织起来,组件间数据流向类似于瀑布
数据流向总是从祖先到子孙(从根到叶子),不会逆流
props:管道state:水源
单项数据流是由状态丢弃机制决定的,具体表现为:
状态变化引发的数据及UI变化都只会影响下方的组件
渲染视图时向下流,表单交互能回来,引发另一次向下渲染
单向数据流是对渲染视图过程而言的,子孙的state如何改变都不会影响祖先,除非通知祖先更新其state
state与props
state是最小可变状态集,特点:
私有的。由组件自身完全控制,而不是来自上方
可变的。会随时间变化
独立存在。无法通过其他
state或者props计算出来
props是不可变的,仅用来填充视图模版:
props React Element描述对象
-----> 组件 ---------------------> 视图
数据绑定?
2个环节
依赖收集(静态依赖/动态依赖)
监听变化
首次渲染时收集data-view的映射关系,后续确认数据变化后,更新数据对应的视图
3种实现方式
| 实现方式 | 依赖收集 | 监听变化 | 案例 |
|---|---|---|---|
| getter & setter | getter | setter监听变化 | Vue |
| 提供数据模型 | 解析模版 | 所有数据操作都走框架API,通知变化 | Ember |
| 脏检查 | 解析模版 | 在合适的时机,取最新的值和上次的比较,检查变化 | Angular |
| 虚拟DOM diff | 几乎不收集 | setState通知变化 | React |
从依赖收集的粒度来看:
Vue通过
getter动态收集依赖粒度最细,最精确Ember和Angular都是通过静态模版解析来找出依赖
React最粗枝大叶,几乎不收集依赖,整个子树重新渲染
state变化时,重新计算对应子树的内部状态,对比找出变化(diff),然后在合适的时机应用这些变化(patch)
细粒度的依赖收集是精确DOM更新的基础(哪些数据影响哪个元素的哪个属性),无需做额外的猜测和判断,框架如果明确知道影响的视图元素/属性是哪些的话,就可以直接做最细粒度的DOM操作
虚拟DOM diff算法
React不收集依赖,只有2个已知条件:
这个
state属于哪个组件这个
state变化只会影响对应子树
子树范围对于最终视图更新需要的DOM操作而言太大了,需要细化(diff)
tree diff
树的diff是个相对复杂(NP)的问题,先考虑一个简单场景:
A A'
/ \ ? / | \
B C -> G B C
/ \ | | |
D E F D E
diff(treeA, treeA')结果应该是:
1.insert G before B
2.move E to F
3.remove F
如果要计算机来做的话,增和删好找,移的判定就比较复杂了,首先要把树的相似程度量化(比如加权编辑距离),并确定相似度为多少时,移比删+增划算(操作步骤更少)
React diff
对虚拟DOM子树做diff就面临这样的问题,考虑DOM操作场景的特点:
局部小改动多,大片的改动少(性能考虑,用显示隐藏来规避)
跨层级的移动少,同层节点移动多(比如表格排序)
假设:
假设不同类型的元素对应不同子树(不考虑“向下看子树结构是否相似”,
移的判断就没难度了)前后结构都会带有唯一的
key,作为diff依据,假定同key表示同元素(降低比较成本)
这样tree diff问题就被简化成了list diff(字符串编辑问题):
遍历新的,找出 增/移
遍历旧的,找出 删
本质是一个很弱的字符串编辑算法,所以,即便不考虑diff开销,单从最终的实际DOM操作来看,性能也不是最优的(相比手动操作DOM)
另外,保险起见,React还提供了shouldComponentUpdate钩子,允许人工干预diff过程,避免误判
状态管理
状态共享与传递
兄弟 -> 兄弟。提升共享状态,保证自上而下的单向数据流
子 -> 父。由父预先传入cb(函数props)
? -> 远房亲戚。远距离通信很难解决,需要手动接力,要么通过context共享
通过提升状态来共享,能减少孤立状态,减少bug面,但毕竟比较麻烦。组件间远距离通信问题没有好的解决方案
另一个问题是在复杂应用中,状态变化(setState)散落在各个组件中,逻辑过于分散,存在维护上的问题
Flux
为了解决状态管理的问题,提出了Flux模式,目标是让数据可预测
基本思路
(state, action) => state
具体做法
用显式数据,不用衍生数据(先声明后使用,不临时造数据)
分离数据和视图状态(把数据层抽出来)
避免级联更新带来的级联影响(M与V之间互相影响,数据流不清楚)
结构
产生action 传递action update state
view交互 -----------> dispatcher -----------> stores --------------> views
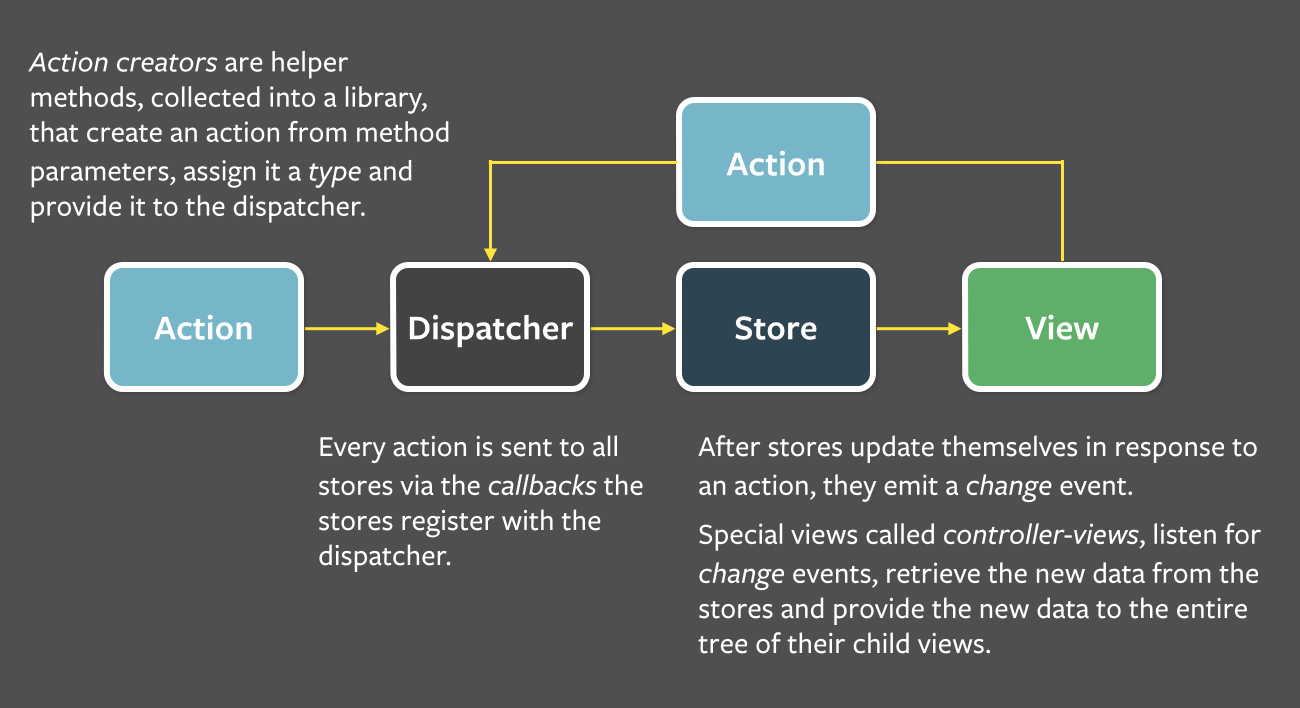
特点是store比较重,负责根据action更新内部state及把state变化同步到view
container与view
container其实就是controller-view:
用来控制view的React组件
基本职能是收集来自store的信息,存到自己的state里
不含props和UI逻辑
Redux的取舍
action 与Flux一样,就是事件,带有type和data(payload)
同样手动dispatch action
---
store 与Flux功能一样,但全局只有1个,实现上是一颗不可变的状态树
分发action,注册listener。每个action经过层层reducer得到新state
---
reducer 与arr.reduce(callback, [initialValue])作用类似
reducer相当于callback,输入当前state和action,输出新state
call new state
action --> store ------> reducers -----------> view
用一棵不可变状态树维护整个应用的状态,无法直接改变,发生变化时,通过action和reducer创建新的对象
reducer的概念相当于node中间件,或者gulp插件,每个reducer负责状态树的一小部分,把一系列reducer串联起来(把上一个reducer的输出作为当前reducer的输入),得到最终输出state
对比Flux
把store数量限定为1
去掉了dispatcher,把action传递给所有顶层reducer,流向相应子树
把根据action更新内部state的部分独立出来,分解到各reducer
能去掉dispatcher是因为纯函数reducer可以随便组合,不需要额外管理顺序
react-redux
Redux与React没有任何关系,Redux作为状态管理层可以配合任何UI方案使用,例如backbone、angular、React等等
react-redux用来处理new state -> view的部分,也就是说,新state有了,怎样同步视图?
container
container是一种特殊的组件,不含视图逻辑,与store关系紧密。从逻辑功能上看就是通过store.subscribe()读取状态树的一部分,作为props传递给下方的普通组件(view)
connect()
一个看起来很神奇的API,主要做3件事:
生成container
负责把dispatch和state数据作为props注入下方普通组件
内置性能优化,避免不必要的更新(内置shouldComponentUpdate)
Provider是怎么回事?
目的:避免手动逐层传递store
实现:在顶层通过context注入store,让下方所有组件共享store
生态
调试工具 DevTools
平台 React Native
组件库 antd Material-UI
发展 Rax
状态管理层 Redux Saga Dva
why-did-you-update React性能优化工具
Under-the-hood-ReactJS React完整逻辑流程图
React Doc | Optimizing Performance